Data Lake Metadata Catalog
Data Lake Metadata Catalog - Simplifies setting up, securing, and managing the data lake. A data catalog serves as a comprehensive inventory of the data assets stored within the data lake. Metadata management tools automatically catalog all data ingested into the data lake. It provides users with a detailed understanding of the available datasets,. It is designed to provide an interface for easy discovery of data. A data catalog contains information about all assets that have been ingested into or curated in the s3 data lake. Better collaboration using improved metadata curation, search, and discovery for data lakes with oracle cloud infrastructure data catalog’s new release; Internally, an iceberg table is a collection of data files (typically stored in columnar formats like parquet or orc) and metadata files (typically stored in json or avro) that. The onelake catalog is a centralized platform that allows users to discover, explore, and manage their data assets across the organization. Make data catalog seamless by integrating with. It exposes a standard iceberg rest catalog interface, so you can connect the. Data catalogs help connect metadata across data lakes, data siloes, etc. A data catalog contains information about all assets that have been ingested into or curated in the s3 data lake. We’re excited to announce fivetran managed data lake service support for google’s cloud storage. Simplifies setting up, securing, and managing the data lake. You will use the service to secure and ingest data into an s3 data lake, catalog the data, and. It provides users with a detailed understanding of the available datasets,. Modern data catalogs even support active metadata which is essential to keep a catalog refreshed. The following diagram shows how the centralized catalog connects data producers and data consumers in the data lake. On the other hand, a data lake is a storage. A data catalog plays a crucial role in data management by facilitating. Lake formation centralizes data governance, secures data lakes, and shares data across accounts. We’re excited to announce fivetran managed data lake service support for google’s cloud storage. By ensuring seamless integration with existing systems, data lake metadata management can streamline metadata workflows, promote data reuse, and foster a. Examples include the collibra data. A data catalog serves as a comprehensive inventory of the data assets stored within the data lake. It exposes a standard iceberg rest catalog interface, so you can connect the. Make data catalog seamless by integrating with. Internally, an iceberg table is a collection of data files (typically stored in columnar formats like parquet or. By ensuring seamless integration with existing systems, data lake metadata management can streamline metadata workflows, promote data reuse, and foster a more. Automatically discovers, catalogs, and organizes data across s3. By capturing relevant metadata, a data catalog enables users to understand and trust the data they are working with. Data catalog is also apache hive metastore compatible that. The centralized. You will use the service to secure and ingest data into an s3 data lake, catalog the data, and. Automatically discovers, catalogs, and organizes data across s3. In this post, you will create and edit your first data lake using the lake formation. The metadata repository serves as a centralized platform, such as a data catalog or metadata lake, for. Automatically discovers, catalogs, and organizes data across s3. In this post, you will create and edit your first data lake using the lake formation. A data catalog contains information about all assets that have been ingested into or curated in the s3 data lake. The metadata repository serves as a centralized platform, such as a data catalog or metadata lake,. R2 data catalog is a managed apache iceberg ↗ data catalog built directly into your r2 bucket. You will use the service to secure and ingest data into an s3 data lake, catalog the data, and. A data catalog contains information about all assets that have been ingested into or curated in the s3 data lake. A data catalog is. Data catalog is a database that stores metadata in tables consisting of data schema, data location, and runtime metrics. Lake formation uses the data catalog to store and retrieve metadata about your data lake, such as table definitions, schema information, and data access control settings. Data catalog is also apache hive metastore compatible that. Make data catalog seamless by integrating. Automatically discovers, catalogs, and organizes data across s3. Modern data catalogs even support active metadata which is essential to keep a catalog refreshed. A data catalog serves as a comprehensive inventory of the data assets stored within the data lake. On the other hand, a data lake is a storage. Lake formation uses the data catalog to store and retrieve. From 700+ sources directly into google’s cloud storage in their. By ensuring seamless integration with existing systems, data lake metadata management can streamline metadata workflows, promote data reuse, and foster a more. The following diagram shows how the centralized catalog connects data producers and data consumers in the data lake. Data catalogs help connect metadata across data lakes, data siloes,. Modern data catalogs even support active metadata which is essential to keep a catalog refreshed. Lake formation centralizes data governance, secures data lakes, and shares data across accounts. Metadata management tools automatically catalog all data ingested into the data lake. From 700+ sources directly into google’s cloud storage in their. Better collaboration using improved metadata curation, search, and discovery for. Lake formation centralizes data governance, secures data lakes, and shares data across accounts. Ashish kumar and jorge villamariona take us through data lakes and data catalogs: You will use the service to secure and ingest data into an s3 data lake, catalog the data, and. The following diagram shows how the centralized catalog connects data producers and data consumers in the data lake. Automatically discovers, catalogs, and organizes data across s3. Data catalog is a database that stores metadata in tables consisting of data schema, data location, and runtime metrics. Data catalogs help connect metadata across data lakes, data siloes, etc. In this post, you will create and edit your first data lake using the lake formation. By capturing relevant metadata, a data catalog enables users to understand and trust the data they are working with. Metadata management tools automatically catalog all data ingested into the data lake. Examples include the collibra data. It provides users with a detailed understanding of the available datasets,. It is designed to provide an interface for easy discovery of data. The onelake catalog is a centralized platform that allows users to discover, explore, and manage their data assets across the organization. A data catalog is a centralized inventory that helps you organize, manage, and search metadata about your data assets. The centralized catalog stores and manages the shared data.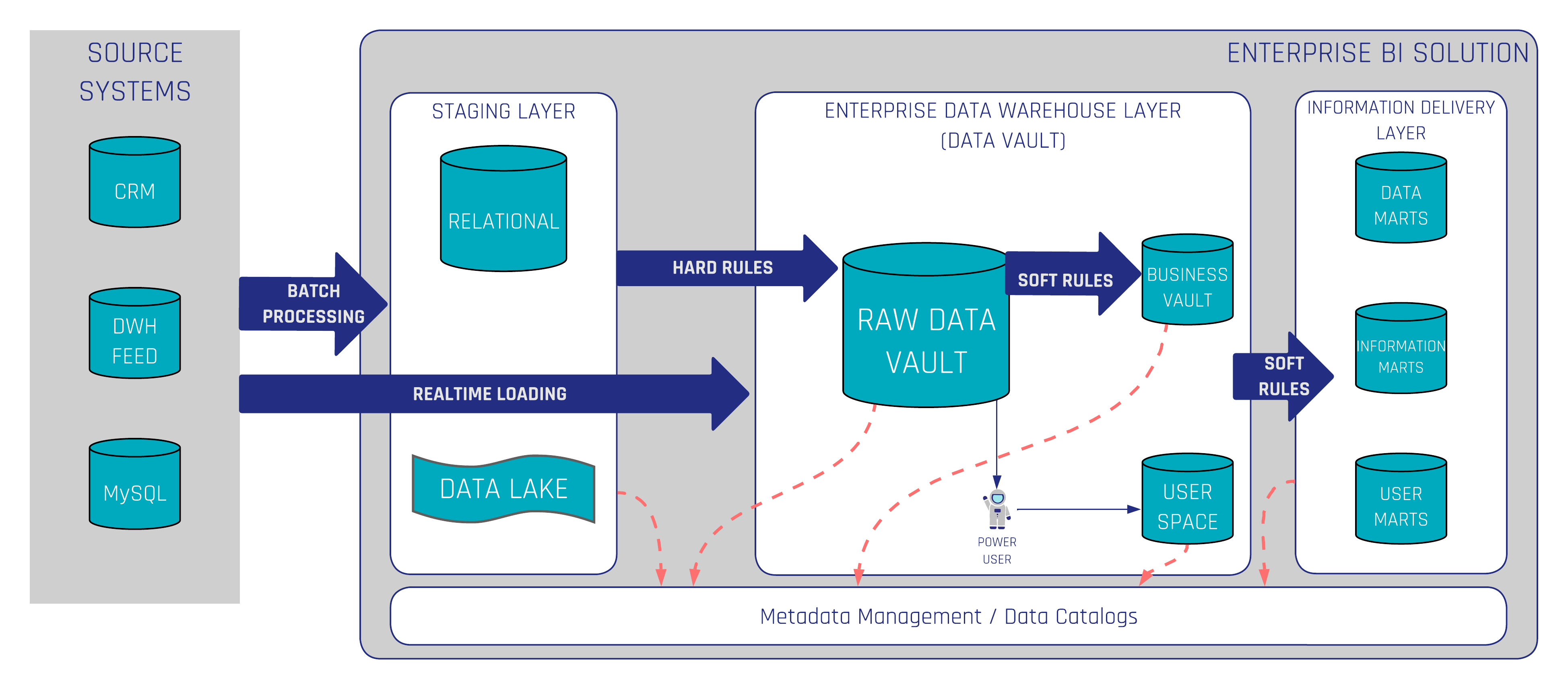
Mastering Metadata Data Catalogs in Data Warehousing with DataHub

Building a Metadata Catalog for your Data Lakes using Amazon Elastics…
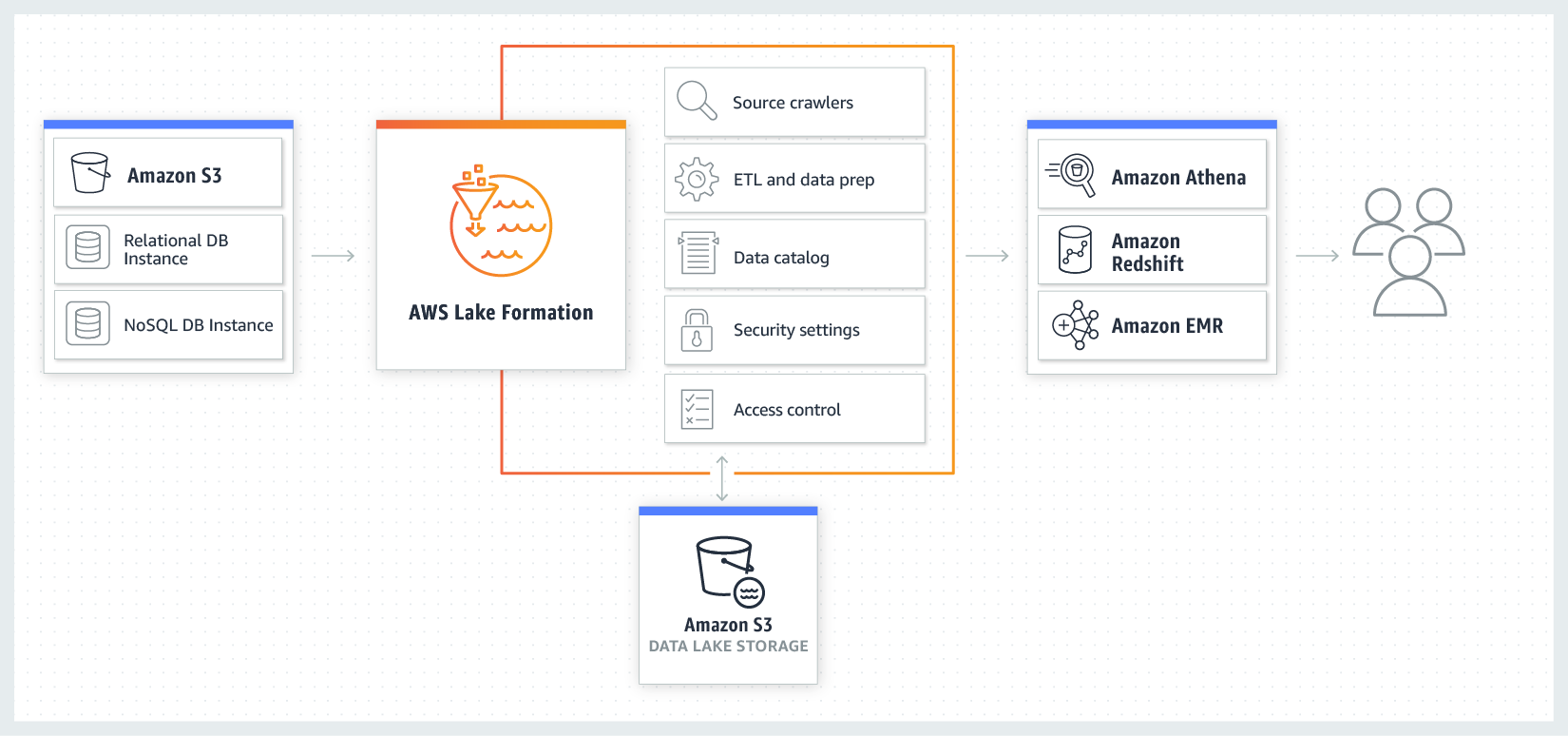
S3 Data Lake Building Data Lakes on AWS & 4 Tips for Success
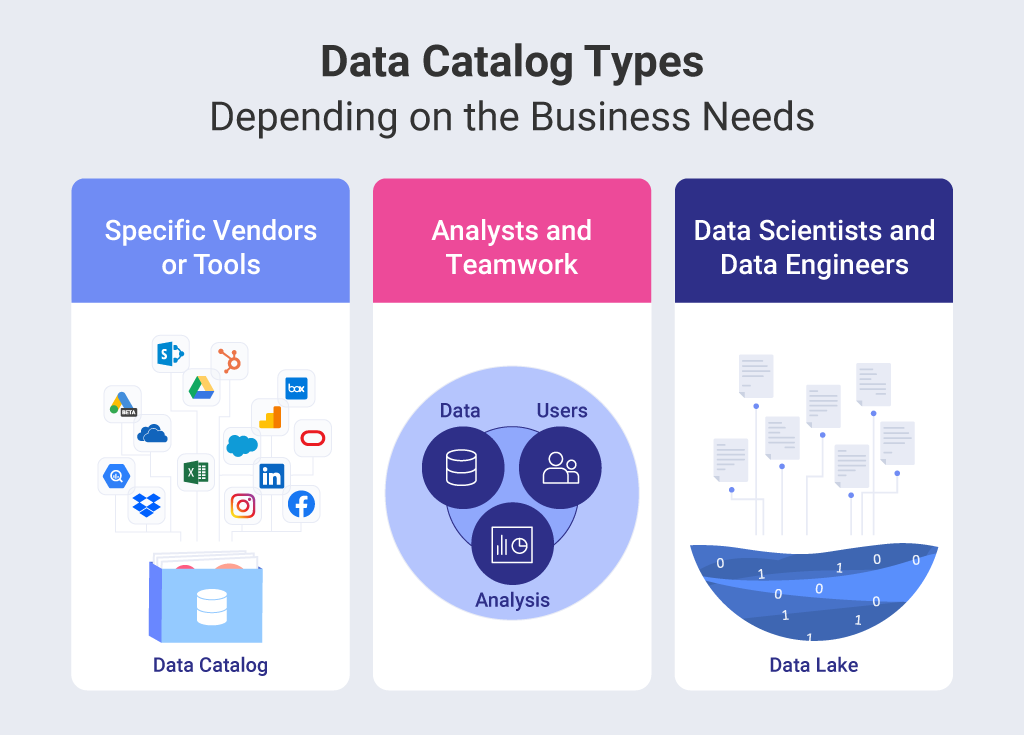
Data Catalog Vs Data Lake Catalog Library
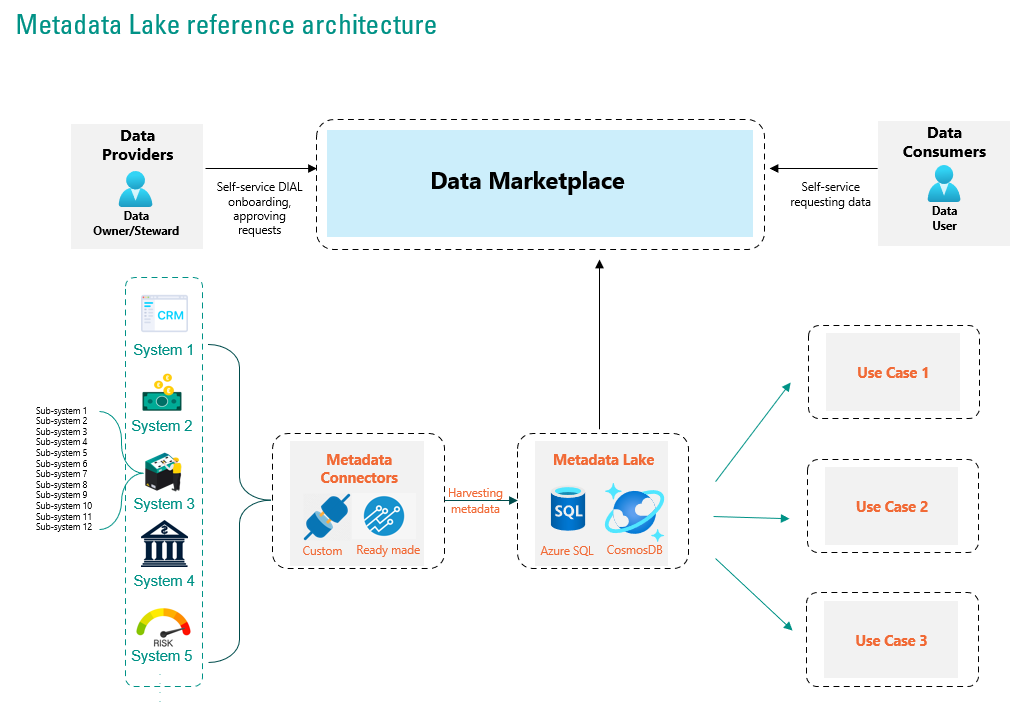
The Role of Metadata and Metadata Lake For a Successful Data
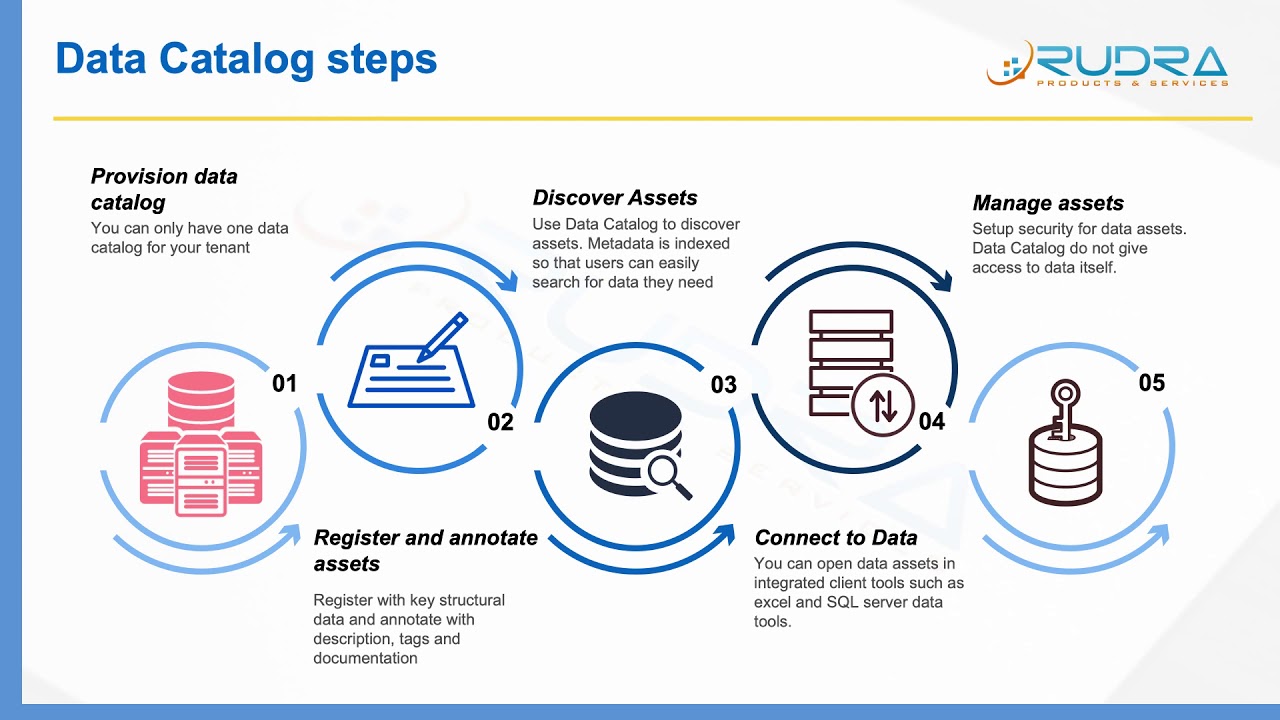
Data Catalog Vs Data Lake Catalog Library vrogue.co
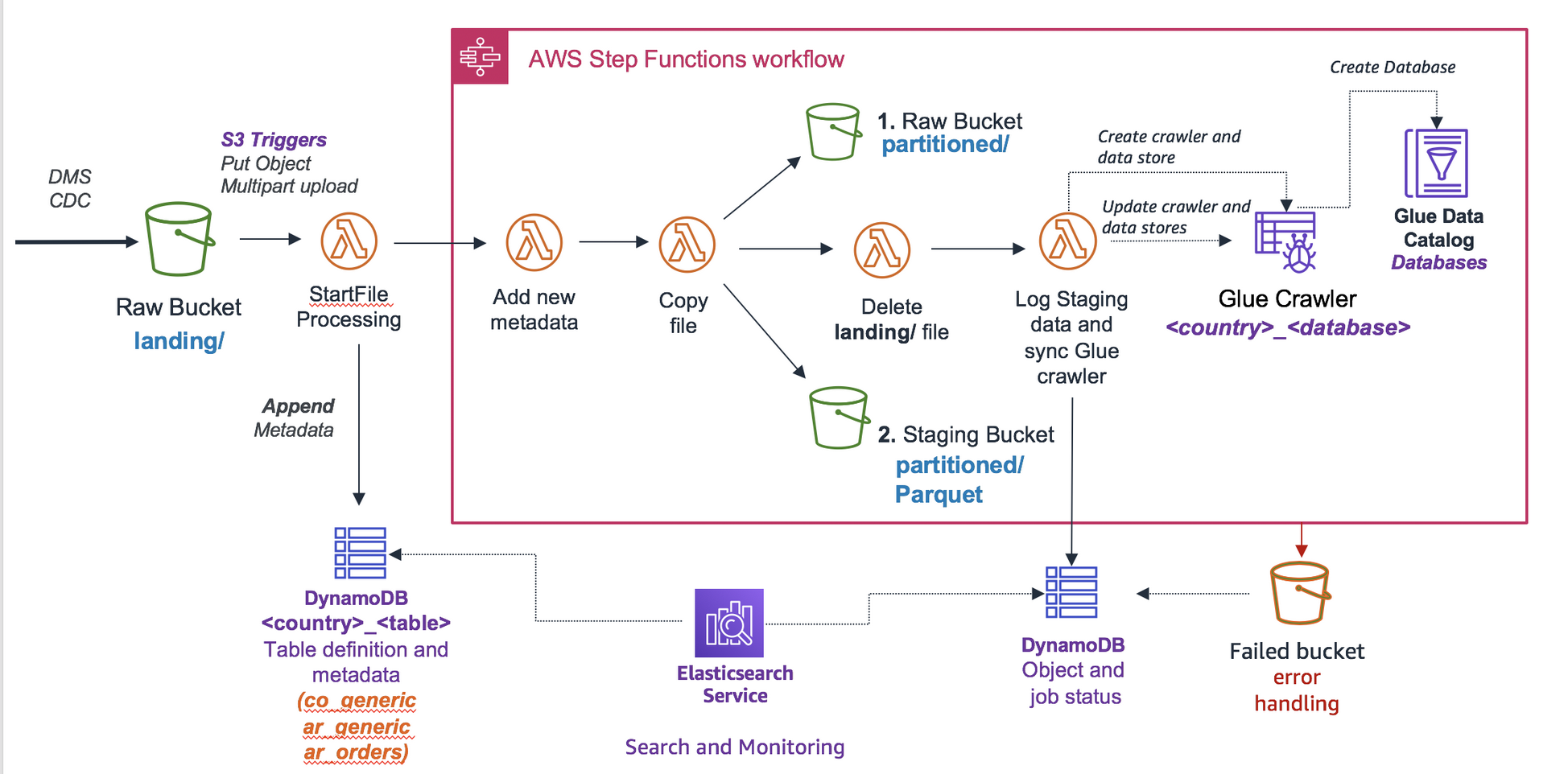
GitHub andresmaopal/datalakestagingengine S3 eventbased engine
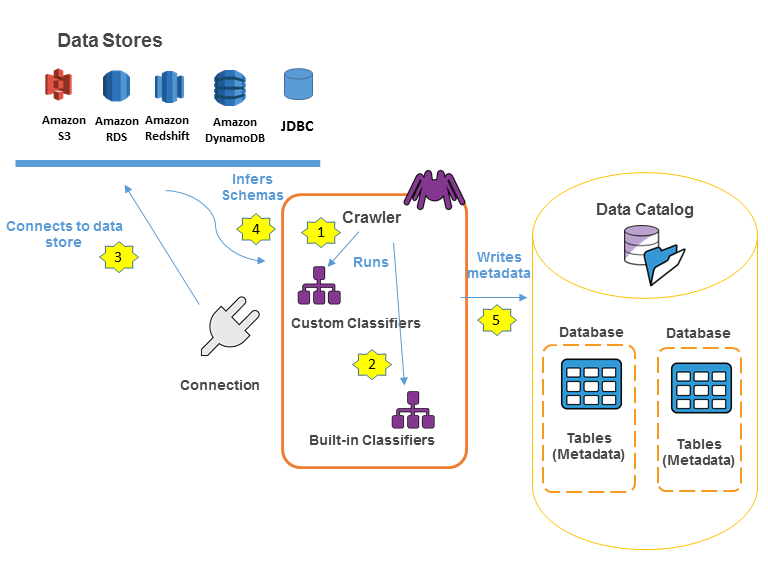
Extract metadata from AWS Glue Data Catalog with Amazon Athena
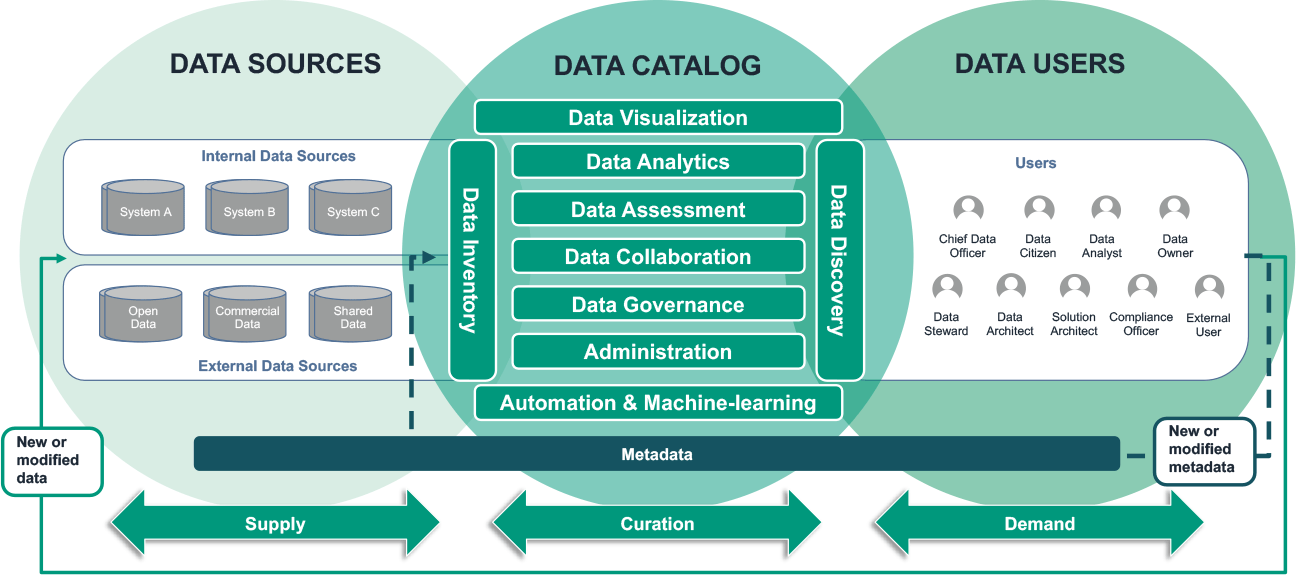
3 Reasons Why You Need a Data Catalog for Data Warehouse
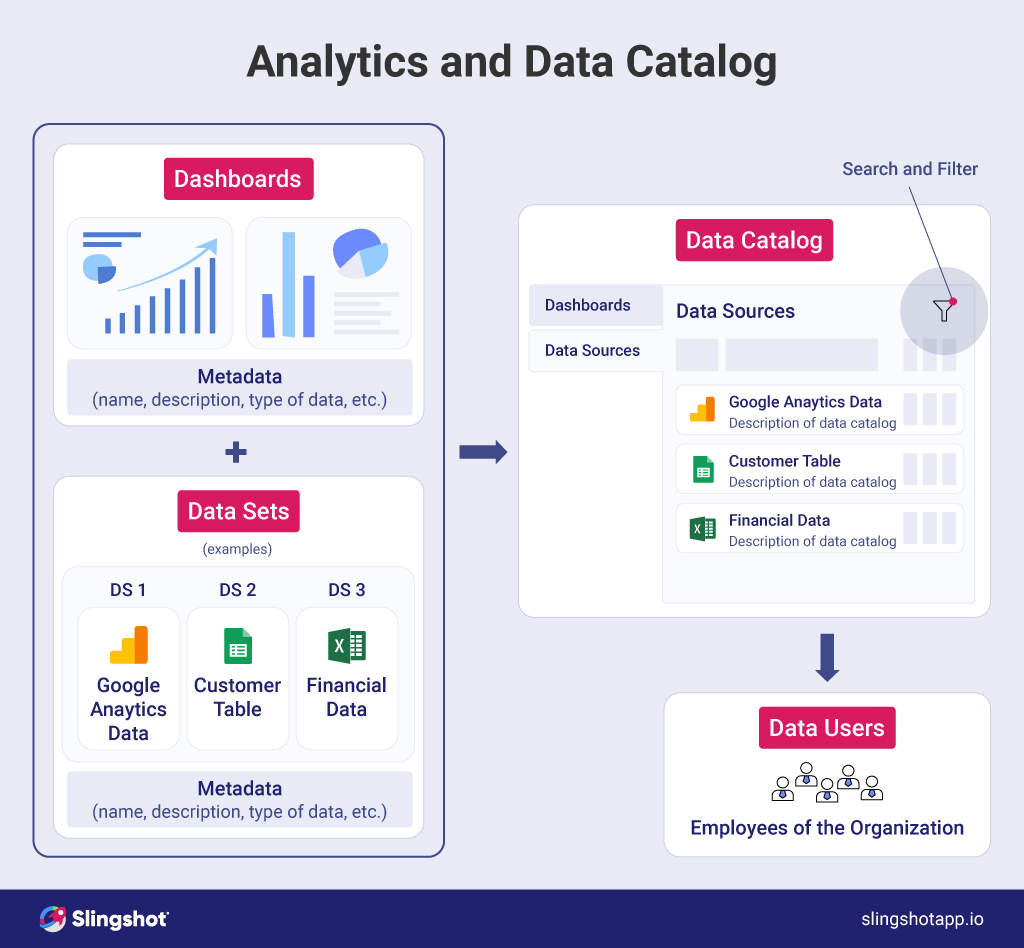
Data Catalog Vs Data Lake Catalog Library
From 700+ Sources Directly Into Google’s Cloud Storage In Their.
A Data Catalog Contains Information About All Assets That Have Been Ingested Into Or Curated In The S3 Data Lake.
It Uses Metadata And Data Catalogs To Make Data More Searchable And Structured, Helping Teams Discover And Use The Right Data Faster.
Make Data Catalog Seamless By Integrating With.
Related Post: