Spark Catalog
Spark Catalog - One of the key components of spark is the pyspark.sql.catalog class, which provides a set of functions to interact with metadata and catalog information about tables and databases in. See the source code, examples, and version changes for each. Catalog is the interface for managing a metastore (aka metadata catalog) of relational entities (e.g. These pipelines typically involve a series of. It allows for the creation, deletion, and querying of tables, as well as access to their schemas and properties. 188 rows learn how to configure spark properties, environment variables, logging, and. We can create a new table using data frame using saveastable. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. A spark catalog is a component in apache spark that manages metadata for tables and databases within a spark session. Database(s), tables, functions, table columns and temporary views). Is either a qualified or unqualified name that designates a. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. Learn how to use the catalog object to manage tables, views, functions, databases, and catalogs in pyspark sql. See the methods, parameters, and examples for each function. Check if the database (namespace) with the specified name exists (the name can be qualified with catalog). Learn how to use pyspark.sql.catalog to manage metadata for spark sql databases, tables, functions, and views. See the methods and parameters of the pyspark.sql.catalog. Caches the specified table with the given storage level. See examples of listing, creating, dropping, and querying data assets. Check if the database (namespace) with the specified name exists (the name can be qualified with catalog). See examples of listing, creating, dropping, and querying data assets. Learn how to use pyspark.sql.catalog to manage metadata for spark sql databases, tables, functions, and views. Learn how to use spark.catalog object to manage spark metastore tables and temporary views in pyspark. See. One of the key components of spark is the pyspark.sql.catalog class, which provides a set of functions to interact with metadata and catalog information about tables and databases in. Check if the database (namespace) with the specified name exists (the name can be qualified with catalog). See the methods, parameters, and examples for each function. Learn how to use pyspark.sql.catalog. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. 188 rows learn how to configure spark properties, environment variables, logging, and. See the methods, parameters, and examples for each function. It acts as a bridge between your data and spark's. Database(s), tables, functions, table columns and temporary views). See the methods and parameters of the pyspark.sql.catalog. See examples of listing, creating, dropping, and querying data assets. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. A spark catalog is a component in apache spark that manages metadata for. It allows for the creation, deletion, and querying of tables, as well as access to their schemas and properties. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. See the methods, parameters, and examples for each function. It acts as. See the methods and parameters of the pyspark.sql.catalog. Database(s), tables, functions, table columns and temporary views). See the source code, examples, and version changes for each. Is either a qualified or unqualified name that designates a. Catalog is the interface for managing a metastore (aka metadata catalog) of relational entities (e.g. One of the key components of spark is the pyspark.sql.catalog class, which provides a set of functions to interact with metadata and catalog information about tables and databases in. How to convert spark dataframe to temp table view using spark sql and apply grouping and… 188 rows learn how to configure spark properties, environment variables, logging, and. Learn how to. Learn how to use pyspark.sql.catalog to manage metadata for spark sql databases, tables, functions, and views. It acts as a bridge between your data and spark's query engine, making it easier to manage and access your data assets programmatically. R2 data catalog exposes a standard iceberg rest catalog interface, so you can connect the engines you already use, like pyiceberg,. We can create a new table using data frame using saveastable. Caches the specified table with the given storage level. How to convert spark dataframe to temp table view using spark sql and apply grouping and… Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and. It allows for the creation, deletion, and querying of tables, as well as access to their schemas and properties. See the source code, examples, and version changes for each. Check if the database (namespace) with the specified name exists (the name can be qualified with catalog). Caches the specified table with the given storage level. One of the key components. To access this, use sparksession.catalog. Catalog is the interface for managing a metastore (aka metadata catalog) of relational entities (e.g. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. A spark catalog is a component in apache spark that manages metadata for tables and databases within a spark session. Caches the specified table with the given storage level. See examples of listing, creating, dropping, and querying data assets. We can also create an empty table by using spark.catalog.createtable or spark.catalog.createexternaltable. These pipelines typically involve a series of. It allows for the creation, deletion, and querying of tables, as well as access to their schemas and properties. Learn how to use the catalog object to manage tables, views, functions, databases, and catalogs in pyspark sql. Database(s), tables, functions, table columns and temporary views). Learn how to use spark.catalog object to manage spark metastore tables and temporary views in pyspark. Is either a qualified or unqualified name that designates a. See examples of creating, dropping, listing, and caching tables and views using sql. R2 data catalog exposes a standard iceberg rest catalog interface, so you can connect the engines you already use, like pyiceberg, snowflake, and spark.
Pyspark — How to get list of databases and tables from spark catalog
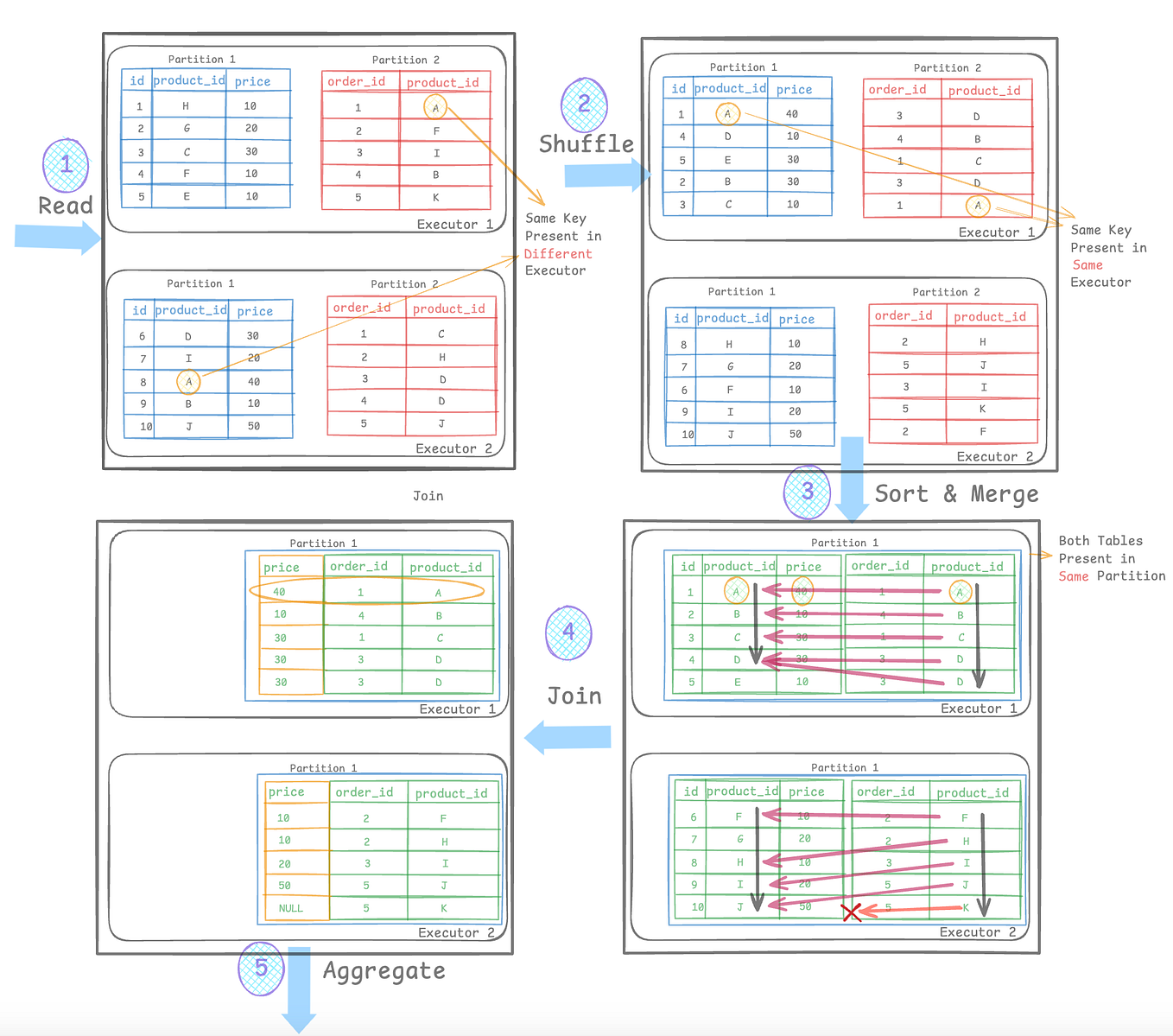
Pyspark — How to get list of databases and tables from spark catalog
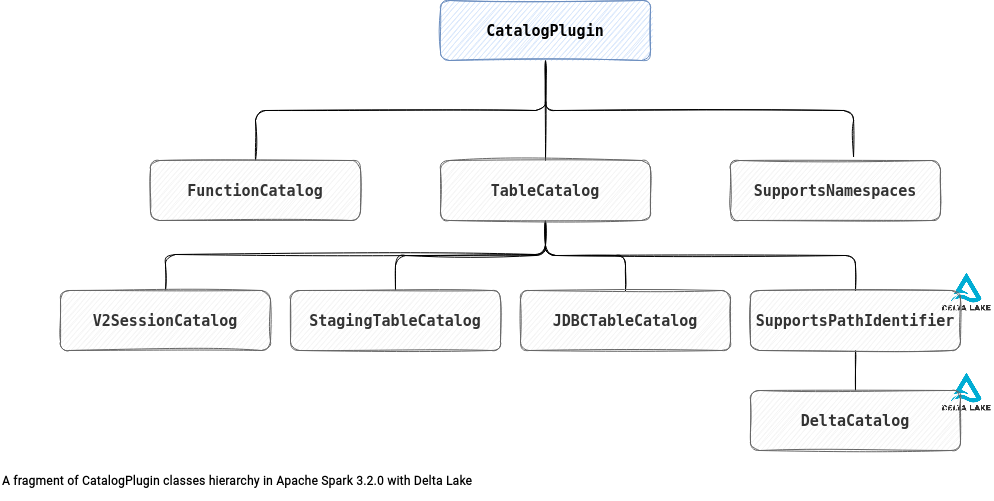
Pluggable Catalog API on articles about Apache
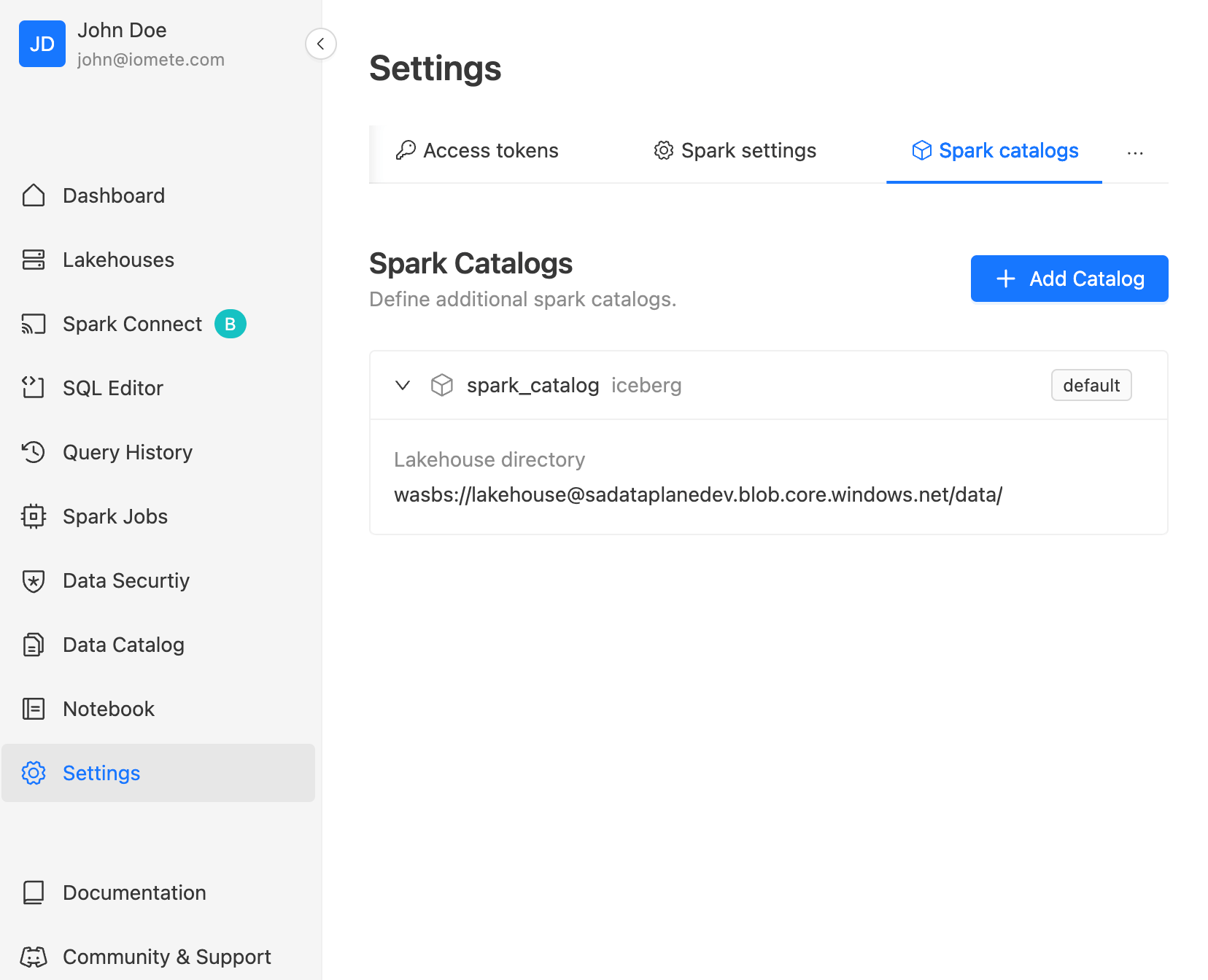
Spark Catalogs IOMETE

Configuring Apache Iceberg Catalog with Apache Spark
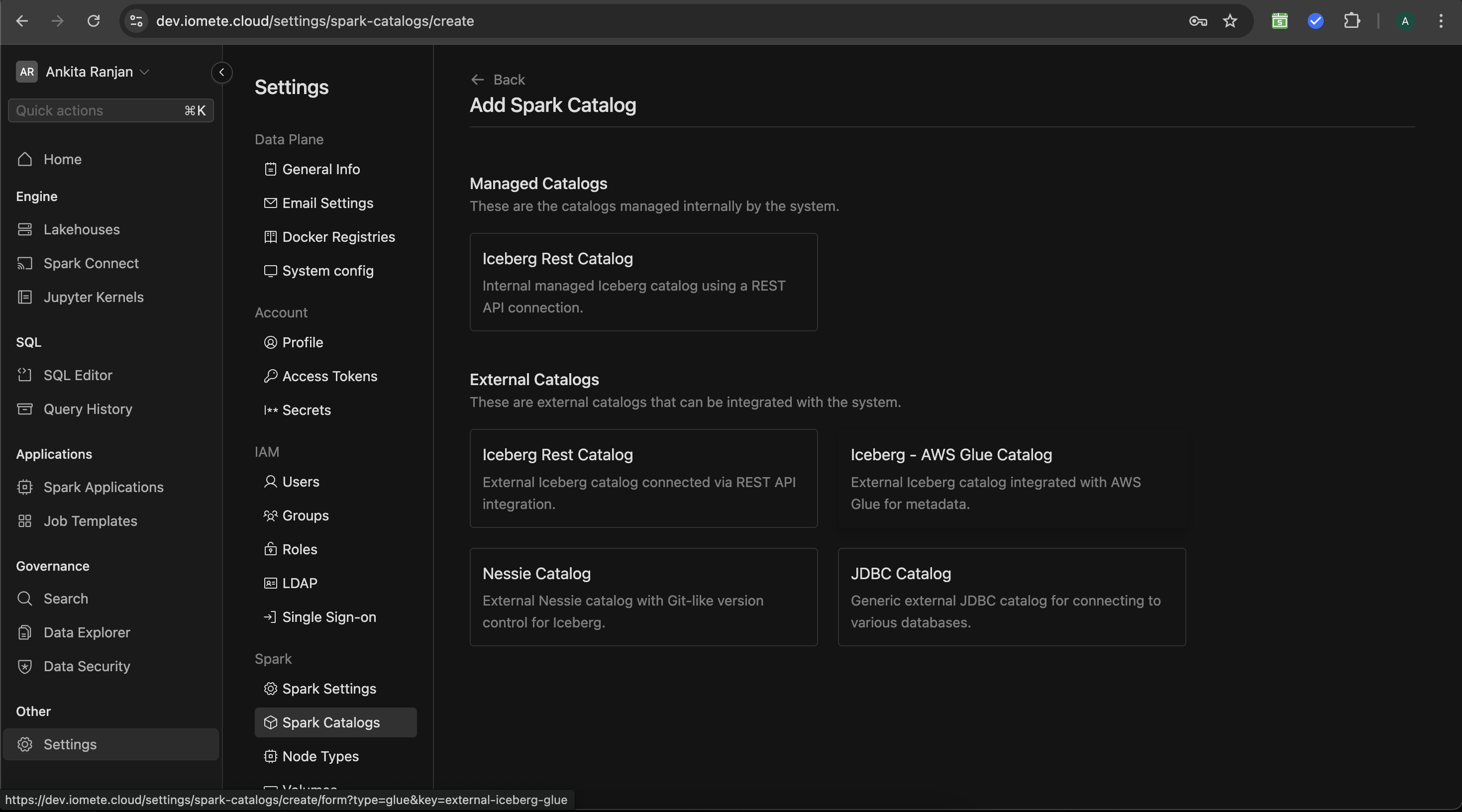
Spark Catalogs Overview IOMETE

DENSO SPARK PLUG CATALOG DOWNLOAD SPARK PLUG Automotive Service

SPARK PLUG CATALOG DOWNLOAD

SPARK PLUG CATALOG DOWNLOAD
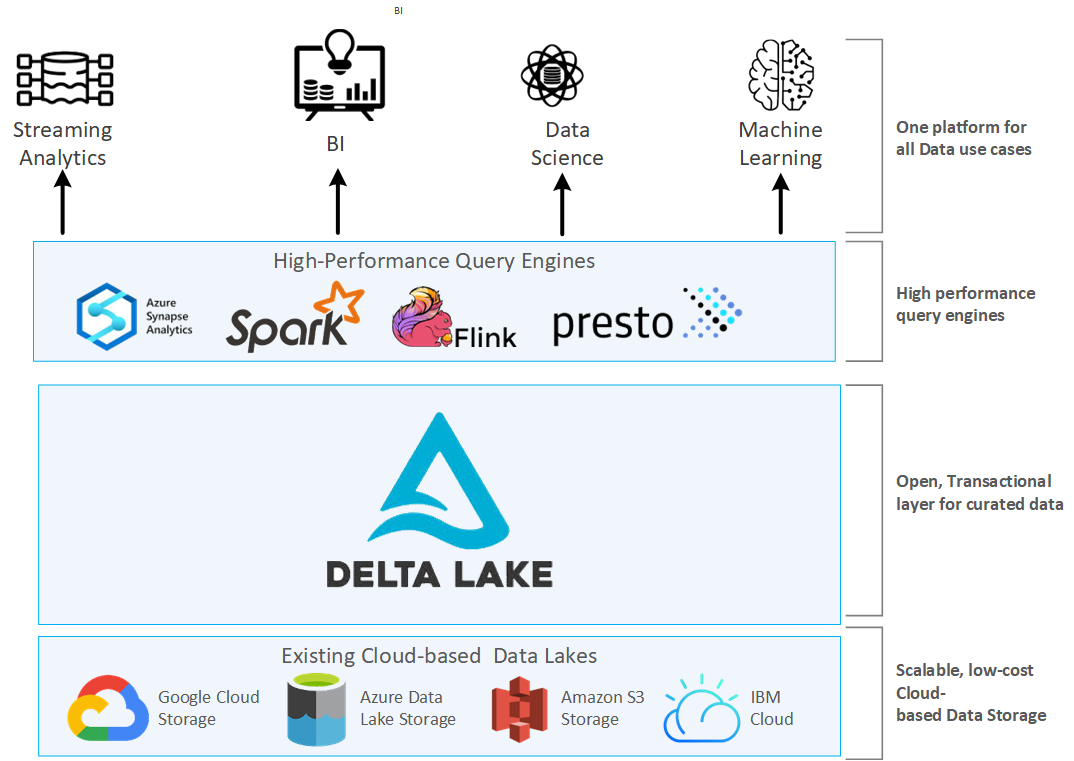
Spark JDBC, Spark Catalog y Delta Lake. IABD
One Of The Key Components Of Spark Is The Pyspark.sql.catalog Class, Which Provides A Set Of Functions To Interact With Metadata And Catalog Information About Tables And Databases In.
Check If The Database (Namespace) With The Specified Name Exists (The Name Can Be Qualified With Catalog).
188 Rows Learn How To Configure Spark Properties, Environment Variables, Logging, And.
See The Methods, Parameters, And Examples For Each Function.
Related Post: